Reinforcement learning (RL) has led to impressive robot demos, but deploying these controllers in the real world remains challenging. Training a policy in simulation is one thing, making it work reliably on a physical robot is another. The hidden costs include months of fine-tuning, poor generalization across tasks, and an unpredictable trial-and-error process.
Credit: π0: First Generalist Policy by Physical Intelligence (π)
A recent paper on π0: A Vision-Language-Action Flow Model for General Robot Control introduces a foundation model for robotics, designed to overcome these limitations. Instead of training separate RL policies for each task, π0 is pre-trained on over 10,000 hours of diverse robot data across multiple platforms and 68 tasks. It builds on pre-trained vision-language models (VLMs) to incorporate internet-scale knowledge, allowing it to follow language instructions and generalize more effectively to new scenarios.
Unlike traditional RL, which requires reward engineering, π0 uses flow matching, a generative modeling technique that enables precise, continuous robot actions. The model follows a pre-training and fine-tuning paradigm, similar to large language models, where it first learns broad robotic skills and is then refined on specific high-quality datasets. This structure helps it tackle complex multi-stage tasks like laundry folding, table cleaning, and box assembly.
How Far Does This Actually Get Us?
While π0 demonstrates impressive zero-shot and few-shot adaptation, it doesn’t completely solve the challenges of deploying robots in the real world. Pre-training on diverse data improves generalization, but physical interactions remain fundamentally different from text or image-based tasks. Unlike large language models, robots must deal with real-world physics, unexpected failures, and hardware-specific constraints, challenges that are difficult to capture fully in data.
Moreover, while flow matching reduces reliance on handcrafted reward functions, it doesn’t eliminate the need for fine-tuning. Many real-world applications will still require manual intervention, domain-specific adaptation, and extensive testing before deployment.
Does π0 represent a major step forward? Absolutely. But is it the final answer to making robots as adaptable as humans? Not yet. Instead of replacing traditional control methods entirely, foundation models like π0 are more likely to serve as a powerful starting point, reducing but not eliminating the need for specialized tuning.
If we want truly generalist robots, progress in hardware, more efficient real-world adaptation, and better failure recovery strategies will be just as important as advances in AI models.
Part II - FAST
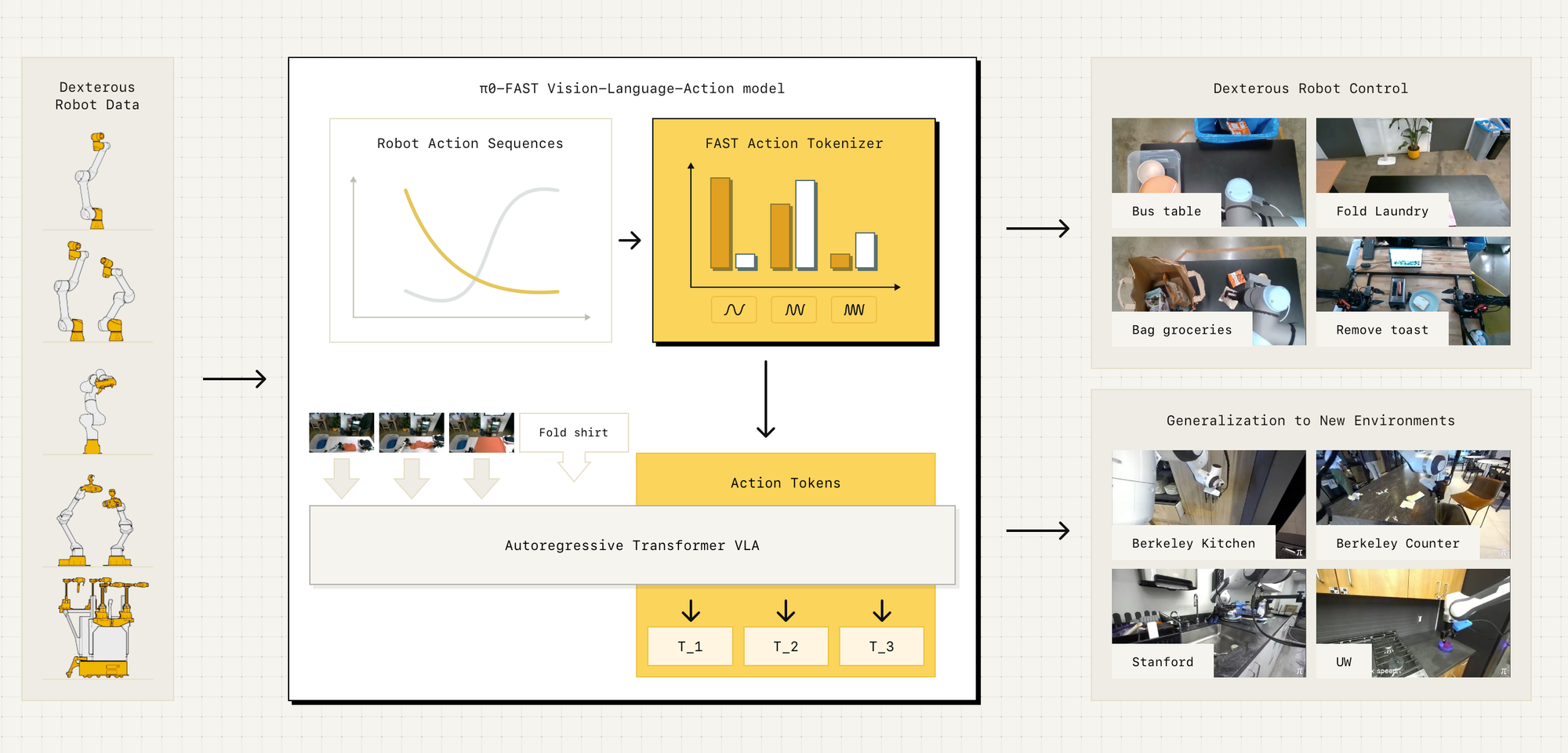
Let's talk about this paper, FAST: Efficient Action Tokenization for Vision-Language-Action Models, is about making robot learning more efficient by improving how robot movements are represented when training AI models.
Right now, when we train AI models for robots, we need to convert real-world movements (which are continuous, like smoothly moving your hand) into a format that a Transformer-based AI model can understand. This process is called action tokenization. However, existing methods for this are too slow and inefficient, especially for tasks that require very precise or fast movements, like folding laundry or flipping a pancake.
How Does This Relate to π0?
You previously read about π0, which is a general-purpose AI model for robots. π0 is trying to teach robots many tasks at once, rather than training a new AI model for each individual task. However, to do this, π0 still needs an efficient way to process robot movements.
That’s where FAST comes in so What Does FAST Do?
Instead of using old-school, inefficient methods for representing robot movements, FAST introduces a new way to compress robot actions using something called the Discrete Cosine Transform (DCT). This is the same type of math used in JPEG image compression. You might wondering..........
🤷🏽♂️ What Does JPEG Compression Have to Do with Robots?

Let me explain the JPEG reference in a way that makes sense in the context of FAST.
JPEG is a widely used format for compressing images. But how does it actually work? Instead of storing every pixel in an image exactly as it is, JPEG converts the image into a different format where it can store the most important details efficiently and remove unnecessary information.
This is done using something called the Discrete Cosine Transform (DCT), a mathematical technique that breaks down an image into different frequency components.
- Low frequencies capture the big, smooth parts of an image (like the general shape of an object).
- High frequencies capture tiny details (like sharp edges or textures).
- JPEG removes some of the high-frequency details that the human eye won’t notice much, reducing the file size while keeping the image looking nearly the same.
How Does This Relate to FAST?
Robot movements (also called action sequences) are continuous signals, meaning they are smooth, like a person moving their hand. Traditional AI training methods store every small movement separately, which creates a lot of redundant data, making learning inefficient.
FAST applies DCT to robot actions, just like JPEG applies it to images. Instead of storing each tiny movement, FAST captures only the most important motion patterns:
- Low-frequency components represent the overall movement of the robot.
- High-frequency components represent small, fine adjustments.
- By keeping only the important components, FAST compresses the action data, making AI training faster and more efficient.
Why Is This a Big Deal?
- Faster Learning – Instead of training on raw, uncompressed action data, AI models can learn from a more compact and meaningful representation, cutting training time by up to 5x.
- Better for High-Speed Movements – Many robots need to make fast, precise adjustments (like flipping a pancake or handling delicate objects). Traditional methods struggle with this because they treat every frame as equally important. FAST prioritizes the most important movements, making learning more reliable.
- More Generalizable – Just like JPEG can be used to compress any image, FAST can be used to process robot actions across different types of robots and tasks, making it more flexible than previous approaches.
Think of FAST like a video compression algorithm but for robot movements. Instead of storing every tiny detail, it removes unnecessary redundancy, so the AI can focus on what matters most—leading to faster training and better performance.
Is FAST Solving the Same Problems as π0?
Yes, but from a different angle.
- π0 is focused on teaching robots to do many tasks with one AI model.
- FAST is focused on making the training process more efficient by improving how robot actions are represented.
Think of it like this:
- π0 is like a teacher trying to teach a student many different subjects at once
- FAST is like a better textbook that makes it easier for the student to learn more quickly.
In the end, both π0 and FAST are working toward the same goal, making robot learning faster and more scalable but FAST is improving how the data is handled, while π0 is improving how the robot learns from that data.
